ホーム > 資料ダウンロード > 分科会レポート > 科学技術計算分科会 2012年度会合
科学技術計算分科会2012年度会合 レポート
今年のテーマは「「京」が拓くサイエンスの未来」である。「京」の運用が開始され、様々な成果が出てきている中、実際に「京」を利用しているアプリ-ケーションが何を目指しているのか、「京」で何ができるのかに注目したテーマである。
まず、企画委員である国立情報学研究所の三浦謙一氏から、HPCIで「京」の運用が始まり、実アプリケーションで本当に性能を出せるようにしていくべきだとの開会の挨拶が行われ、続いて4件の発表が行われた。
 三浦謙一氏(国立情報学研究所) |

|
最初の講演は「スーパーコンピュータの中で生まれる宇宙」という題目で筑波大学の石山 智明氏により行われた。宇宙の約85%は重力を通じて影響を与えるダークマターで満たされており、その重力により密度揺らぎが成長し、ダークマターハローと呼ばれる構造が形成される。このダークマターハローはその重力によりいわゆる私たちが目にする物質を集め、銀河や恒星、惑星が誕生している。そのため、その構造形成について、調べることが重要である。この現象はマルチスケール・マルチフィジックスであるためスーパーコンピュータを使わないと計算できないとのことである。
 石山智明氏(筑波大学) |
|
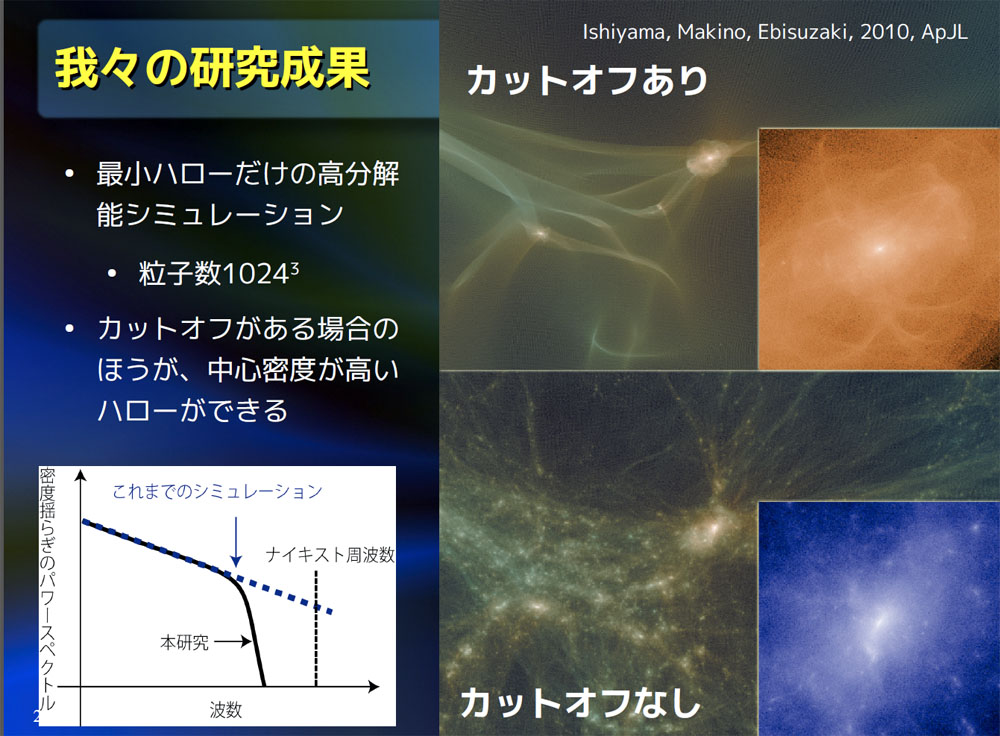
計算としては、ダークマターの分布を離散化し粒子として表し、粒子間の重力相互作用を解くことで計算する重力多体シミュレーションが行われている。ダークマターハローの形成では、密度揺らぎで20桁ほど質量幅があり、すべてのスケールを含んで計算を行うことは「京」を利用しても不可能とのことである。
石山氏らはダークマターの密度揺らぎから生まれる第1世代天体形成を狙って京を利用している。これは世界中の研究者がしのぎを削っているダークマターの初検出に貢献が可能で有り、重要な課題である。それはダークマター検出にはダークマター対消滅が重要で有り、そこを理解するには銀河系ダークマターの微細構造を解明する必要があるからである。石山氏らは最小ハローだけを高分解能シミュレーションを行い、その密度揺らぎ構造を調べた。その結果中心密度が高いハローが得られ、それは大きなハローの進化過程に影響を与える可能性があり、対消滅にも影響があると考えられる。「京」を用いて更に高分解能シミュレーションを行い、最小ハローを正しく理解し、その階層的構造形成過程を追うシミュレーションを目指しているとのことである。
石山氏が用いているシミュレーションコードはTreePM法であり、これは近距離力をTree法、遠距離力をPM法で解く手法である。流れとしては、全空間を分割し、ノードに割り当て粒子を再配分(一部隣接通信発生)、PM法で長距離力の計算(全体通信発生)、Tree法で近距離力を解く(隣接通信発生)。全体通信ではalltoallを全ノードではなく、階層的に行うことで、3〜4倍の性能改善を達成し、「京」を全部使うと47%の実行効率で5Pflopsを達成した。この結果でSC12のGordon Bell Finalistに選ばれているとのことである。
【補足】
SC12で、石山氏はみごとにGordon Bell賞を受賞された。
SC12 Award Recipients
筑波大/理研/東工大記事
次の講演も「京」を利用しているアプリケーションの講演で、東京大学の鷲尾 巧氏による「サルコメア力学から心筋細胞構造を経て心拍動にいたるマルチスケール解析について」の発表であった。鷲尾氏らは分子生物学的なミクロレベルの現象と生理学的なマクロレベルの現象の橋渡しとなるシミュレーションを行っている。ミクロレベルでの動作では、サルコメアが滑り運動することで筋肉が収縮し、マクロレベルの臓器としてのポンプの動きを生み出している。カルシウムイオンが細胞に入ってくることで、サルコメアにおける架橋運動が活性化するが、カルシウムイオンの細胞内濃度変化はバイドメイン方程式を臓器全体で解いて興奮伝播解析を行うことにより求めている。心筋の線維の方向(細胞が収縮する方向)は内膜では90度で、外に行くにつれて回転し、120度くらい変わる(異方性構造)が、これがポンプ機能に大きく貢献している。
 鷲尾巧氏(東京大学) |
(講演スライドは非公開) |
心臓をシミュレーションする場合、現象を平均的なモデルに落とし込み計算をすることが困難である。それはミクロスケールで起きている現象が様々な要因により現象の起き方が変わるため、平均化が難しいためである。そのため、「京」では平均化しない、ありのままのモデルで拍動する心臓モデルを計算することを目標としている。ありのままとはサルコメアの動きから心筋細胞の異方性構造を経て心拍動を計算する。従来はモデルにマクロ的な経験則を導入していたが、これではミクロの効果を全く含めることができない。
この解析手法の実現により, 分子レベルでの状態変化の法則および 細胞組織レベルでの各構造体が心臓の拍動性能やエネルギー消費に関わる効率にどのような影響を与えているのか, 逆にマクロ的な筋肉の変形がフィードバックされて分子レベルでの状態変化にどのような影響をもたらしているのかなどについてシミュレーション結果を通して解析することが可能となった。
このモデルはいわゆる連成計算シミュレーションである。計算はミクロに5657ノード、マクロに128ノードを割り当てており、ミクロの負荷が大きい。
この現象では現実に近いサルコメアのモデル作成が重要であり、実験結果との比較、シミュレーションからの予言が重要な役割を果たしていくと思われる。
3番目の講演は「HPC分野におけるGPU活用技術 〜アクセラレータ技術WG成果報告〜」という題目で2009年10月〜2012年1月まで活動を行ったアクセラレータ技術WGの成果報告であり、九州大学の井上 弘士氏が発表を行った。
 井上弘士氏(九州大学) |
|
WG設置の背景としては、エクサスケールコンピューティングを目指す際に消費電力の壁があることである。そこを越えるためには、既存のマシン(CPU)を単純にスケーリングさせた性能では2018年時点で実現が極めて難しいとの報告がある。そこで質的な変化が必要であると考えられる。そこでGPUのようなアクセラレータが想定され、現時点で一番有望な技術であるGPUを調査対象にし、GPUを使って本当に手軽に性能がでるのか、また、不向きなアプリは本当に不向きなのかを調査した。
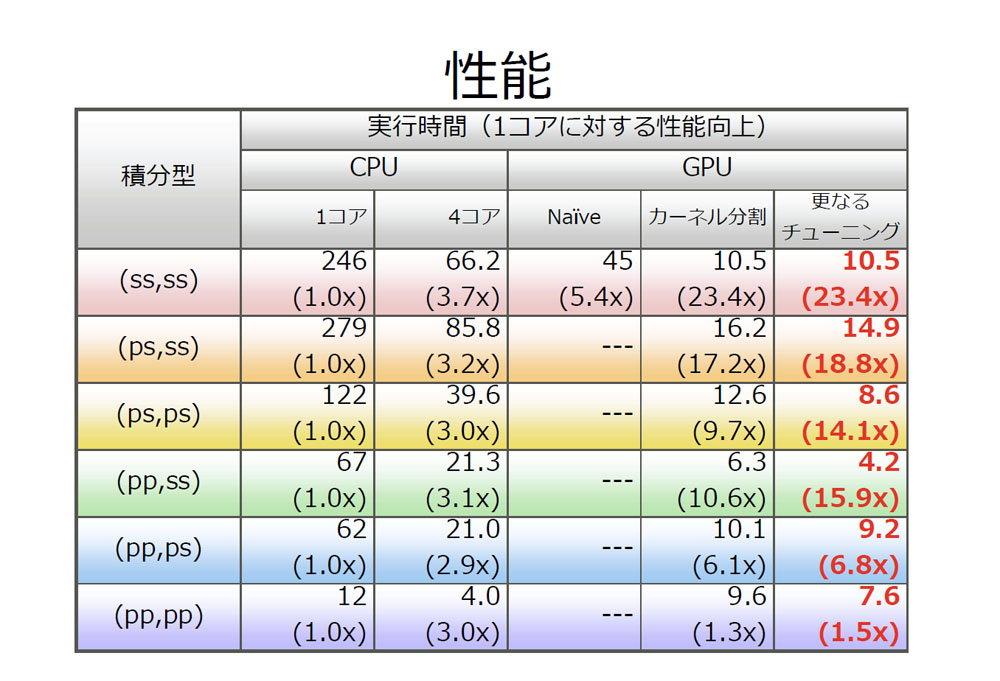
まずPGIアクセラレータを利用し、姫野BMT、2D-FDTD、分子軌道法の3つのプログラムがどう加速されるかを調べた。CUDAで書き下した場合に約50GFlops出る姫野BMT、2D-FDTDは、30分程度のディレクティブ追加で約19G程度出ることが分かった。一方で、分子軌道法はPGIアクセラレータではコードが生成できないという結果であった。
このように分子軌道法はGPUに不向きと考えられるが、実際にCUDAでチューニングした場合、性能が出ないのか調べるためにCUDAでチューニングを行った。計算中99%の実行時間を占めている行列の計算に注目し、ここをチューニングした。ここは4重ループの計算であり、6つのタイプの積分計算が含まれている。まず、比較としてOpenMPで並列化すると4コアで1コアに比べて3.3倍の速度になった。まずCUDA化すると、ある積分計算は5倍程度の速度になるが、一方で速度が上がらない計算もあり、atomic操作がボトルネックになっていた。ここでカーネル分離を行い、atomic操作を減らし、メモリバンド幅をうまく活用すると10倍以上の速度向上になった。更に共有メモリを使いメモリアクセス数を減らし、さらなるチューニングを加えると約12倍程度の性能向上になった。
これらの結果からGPUを利用する場合、アプリを開発する人と実装をする人の協調でうまく使えるのではないかということが示唆されていた。
最後の講演では富士通株式会社の三浦 健一氏により「スーパーコンピュータ「京」でのMPIの実装と評価」というタイトルで、実際に京で用いられているMPI通信について紹介があった。「京」は8万プロセッサをTofuインターコネクトで接続している。Tofuは6次元トーラス構成(XYZ×ABC)で、ICCは高帯域、低遅延、省電力、高信頼性を目指して設計されている。TofuはXYZとABCを組み合わせて仮想3次元トーラスを形成している。Tofuと利点としては、分割されてもトーラスを維持できる(普通のトーラスはメッシュになる)、同様に故障時にもトーラスを維持できることがあげられる。
 三浦健一氏(富士通株式会社) |
|
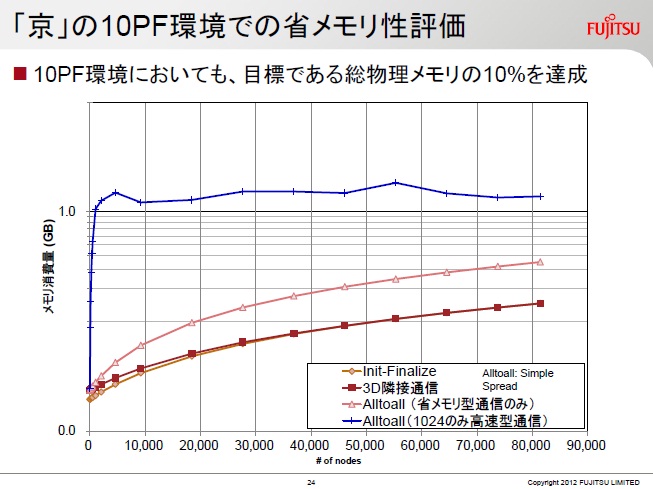
「京」は8万ノードから構成されるなるため、1ノード1プロセスで運用を想定しMPIを実装し、通信に伴うシステムの利用メモリは総メモリの10%以下を目標とした。既存のMPI実装では8万ノードでプロセス間通信に伴う受信バッファにより11.6GBのメモリを消費してしまう。このため大規模並列システムでは受信バッファのメモリ使用量削減が重要となってくる。ただし、メモリ使用量と通信性能はトレードオフの関係であり、注意が必要である。実際のアプリケーションでは、各プロセスの通信相手は限定されている。そのため、高性能通信を割り当てるノードを制限することを考えた。「京」では、初め省メモリ型通信を行い、その後高性能通信を行うルールを導入し、15回通信を行った初めの1024ランクが高速型に移行するようにしている。今回の手法では1.5GBの使用量となった。
集団通信では多重度を上げることでスループットを確保している。分岐により並列性を上げ、中継数を減らしている。「京」では仮想配置を基準に考えている。形状、開始位置に依存しないアルゴリズムにし、基本は軸単位で考える。Bcastでは最終的にはTrinary×3と呼んでいるアルゴリズムを開発し、これにより3in3outを満足している。既存アルゴリズムと比べて11倍の高速化を実現した。Alltoallでは、パケット衝突により性能が出ていないため、パケット衝突の回避を行うためにペーシングを組み込み、理想的な通信を実現するなど集団通信の最適化を施した。これらの評価を10PFlops環境で行うときちんとスケールしていることが示された。 この結果、アプリケーションへは、LinpackやGordonBell賞、HPCCチャレンジなどでの高実行効率の達成に貢献できている。さらにランクの配置についても最適化を行っている。RMATTというランク配置最適化ツールを作成しており、これにより最適なランク配置で計算を行うことが可能となっている。
最後に閉会の挨拶としてJAXAの松尾裕一氏が感謝の言葉を述べて、昼の部が閉会した。

松尾裕一(宇宙航空研究開発機構)
休憩を挟んで開かれた懇談会では「「京」のここが好き!ここが嫌い?」というテーマで、小柳義夫氏をモデレータに、ユーザ側から大野洋介氏、似鳥啓吾氏、長谷川幸弘氏、開発側から住元真司氏、山中栄次氏をパネリストに迎えて、率直な意見交換が行われた。ユーザ側からは「良くも悪くもしっかり手をかければ、使える計算機だ」「C++が利用できるのはうれしいが、性能をもっと改善してほしい」など実際に利用しているからこその意見が出ていた。開発者側としてはもちろん嫌いなところはないが「10PFlopsを達成するための優先開発順位があったが、その大命題を達成したこれからは足りない部分の性能強化を行っていく」という方針を聞くことができた。
 |

|
以上