5. チューニング
GP7000 でのプログラム1 の実行で性能がでていないのはキャッシュミスの発生が原因の1 つと考えられる。そこで、GP7000 用にプログラム1 のチューニングを行ってみる。オリジナルのプログラムでは、行列積の計算は中間積法で次のようになっている。
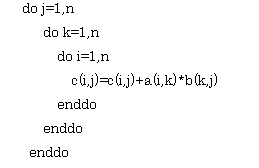
ただし、配列a 、b 、c は倍精度実数型で、変数n の値は2000 である。これをキャッシュブロック化されるように次のようにコーディングする。

これで配列a はir×kr の小行列単位に計算が行われる。GP7000 の一次データキャッシュの容量は1CPU あたり64KB であるから、ir×kr≦8192 の範囲で処理時間が小さくなるir とkr の組を調べればよい。また、キャッシュブロック化したループにループアンローリングを施すとさらに速くなり、k に関するループを展開数4 でアンローリンクしたとき最もよい結果が得られた。
これらのチューニングを行ったものをGP7000 上で測定した結果を表7 に示す。キャッシュブロック化およびループアンローリングを行うと、1CPU で5.9 倍、8CPU で9.0 倍の性能向上が得られた。また、キャッシュブロック化を行うと1CPU と8CPU の比率は8 を越えた。これについては2次キャッシュの効果が考えられる。たとえば、配列b の大きさは32MB であるが、これに対して2次キャッシュの容量は1CPU あたり8MB であるため、1CPU で実行する場合には配列b へアクセスする際に必ず2 次キャッシュミスが発生する。8CPU で実行する場合には各CPU がアクセスする配列b の大きさは8MB よりも小さくなるから2 次キャッシュミスが発生する可能性は少なくなる。

表7: プログラム1 のチューニング結果(GP7000 で測定)
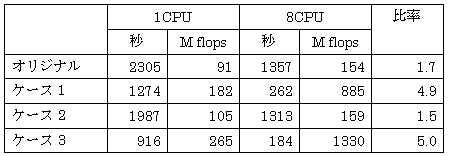
表8: プログラム3 のチューニング結果(SR8000 で測定)
次にSR8000 でのプログラム3 の実行において台数効果がでていない問題を考えてみる。コンパイルリストを調べてみると、do ループ中に含まれる演算量が多すぎるため疑似ベクトル化および要素並列化[2] に失敗したという主旨のメッセージが出力されている部分が2 箇所あった。これらのループは全体の演算処理量からみても大きい部分を占めているため、複数のdo ループに分割することによって処理性能の向上が期待される。また、プログラム3 では実数型変数および配列は単精度で実行されているため拡張レジスタが使用できず、使用可能なレジスタ数が制限されている。よって、倍精度実数型に変更して実行することにより性能向上が見込まれる。
そこで次のようなプログラムの変更を行ってみることにした。
| ケース1 | : | 疑似ベクトル化および要素並列化に失敗した2 つのdo ループを複数のループに分割する |
| ケース2 | : | すべての実数型変数および配列を倍精度にする |
| ケース3 | : | ケース1 とケース2 の変更を同時に行う |
プログラム3 にケース1 ~3 の変更を行ったものをSR8000 上で実測した結果を表8 に示す。オリジナルとケース3 を比較すると、1CPU では2.5 倍、8CPU では7.4 倍の性能向上が得られた。