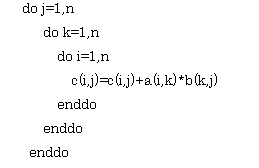[目次]
[発表資料]
質疑応答「共有メモリ型スカラ計算機の処理性能について」
-司会- 航空宇宙技術研究所 福田 正大
- 【司会】
- 今日は、永井先生が体調不良でご欠席のため、代理として富士通の青木さんにご報告いただきました。青木さん、どうもありがとうございました。
代理のご報告なので、全ての質問にお答えいただけないかもしれませんが、ご質疑、コメント等ございましたらお願いします。
- 【中村】(航空宇宙技術研究所)
- 使用されたコンパイラはSUN Fortran77ですよね。
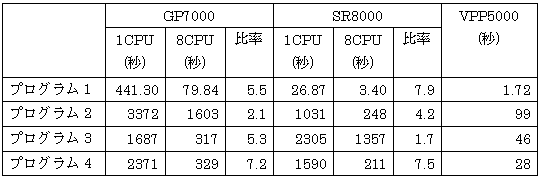
プログラム3は、SRとGPの間で性能が逆転していますが、どうしてそのようなことが起こるのか、理由を教えてください。
- 【青木】(代理発表者:富士通(株)ソフトウェア事業本部ミドルウェア事業部コンパイラ技術部)
- プログラム3に関しては、SRは大きなループが苦手なようで、疑似ベクトル化、および要素並列化をされていない点が原因と思われます。
- 【福田】
- プログラム4は、ピーク性能の観点から考えても、1と0.9で割り算してもまだSRの方が若干よい性能が出ている、ということですね。
- 【中村】
- もう一つ質問です。通常のプログラミングでは性能を引き出すのは難しいということで、コンパイラやチューニングツールの今後に期待したいとありましたが、せっかく青木さんにご報告いただいたので、富士通は今後どのようにその期待に応えていくのかという点について、具体的にお聞かせください。
- 【青木】
- プログラム1の行列積については、一般的なベンダーを含め、ほとんどのベンダーで既に対応していると思います。富士通では、とりあえず年末に出荷する版で、第一次のエンハンスを行っています。今後も継続的に、キャッシュの有効利用という観点で、スカラのチューニングの改善を図ってまいります。
また、例えばプログラム2が8CPUで2.1倍しか並列化効果が出ていない点についてですが、分析した結果、やはりGPはSRよりは並列の解析能力が不足していたと思います。具体的に言いますと、多重のループ解析の問題があり、GPでは最内の方で並列化していたということです。この点に関しては、早急にチューニングを改善しようと思っています。現在は、コンパイラの解析能力による向上分と、メモリのキャッシュ周りの2点が改善のポイントだと思っています。
- 【林】(国立天文台天文学データ解析計算センター)
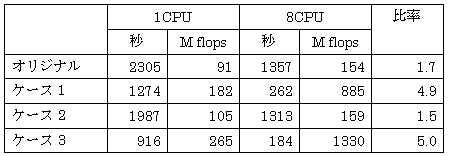
- コメントをさせて下さい。今回の計測で、プログラム3に関してSRの性能が阻害されている一番の大きな理由は、演算をループにまとめているか多数のループに分割しているかという点だと思います。実は私たちも名古屋大学の荻野先生と同じ三次元電磁流体コードで、アルゴリズム等基本的には同じものを使っているのですが、私どもは、多数のループに分割して利用しています。先程、キャッシュの有効利用で、多数のループに分割した方が性能が出ているとのご説明がありましたが、これは、実際に私どもが行なったSRにおける計測でも同じ結果が出ています。ベクトル計算機向けに演算をループにまとめているコードに関して、SRにおいて性能が阻害されている場合は、ケース1の処置、演算を多数のループに分割する処置で、ある程度改善される場合があると思います。
- 【三浦】(富士通(株)コンピュータ事業本部)
- プログラム1のマトリックス・マルチプライに関して、幾つか質問があります。
まず1点目の質問は、この行列積計算のプログラム例についてですが、これは、いわゆるベクトル計算機でよく使うミドルプロダクト法、つまり、ベクトルにベクトルを足しこむ方法なわけですが、私が以前調べた限りでは、むしろスカラの場合は、kを一番内側に持ってきて内積でどんどん足しこむ方が効率が良いように思いましたが、そのような場合との比較例はあるのでしょうか。
- 【青木】
- 現在はありません。しかし、ベクトルプログラミングの資産は世の中に非常にたくさんありますので、これをSMPでも効率よく実行しなければならないという観点では、コンパイラを改善していくつもりです。
- 【三浦】
- 2点目の質問ですが、アンローリングをした場合としない場合の例が出ていますが、アンローリングも深さはいろいろあると思いますが、パラメータサーチのようなことはしているのですか。
- 【青木】
- やっていると思います。
行列積に関しては、後ほど伊奈から詳細をご報告しますので、そちらを参考にしてください。
- 【司会】
- どうもありがとうございました。(拍手)
[目次]
[発表資料]