3. プラズマ粒子シミュレーション
計算結果を紹介する前に、ここで簡単にプラズマ粒子シミュレーションの方法を説明しておきたいと思います。粒子シミュレーションでは実際の粒子数を計算するのはとても無理なので、現実の電子・イオンの1個1個を扱うのではなく電子またはイオンが多数個集まった超粒子を1つの粒子として扱います。粒子の運動方程式を見ればわかるように、超粒子はその(電荷量)/(質量)の値が元の電子・イオンと同じである限りその運動を代表していると考えることができます。超粒子は空間的に広がりを持っており、ちょうど1つの粒子は電荷の雲と見ることができます。電磁場などの場の量は空間的に格子を張りその上に定義します。超粒子は電磁場から力を受けて運動をするわけですが、力は離散化された場の量から超粒子の形状に応じた内挿法で求めます。逆に、電磁場の時間・空間発展はMaxwellの方程式を解くことによって計算するのですが、空間上の電荷密度・電流の分布は超粒子の分布から格子上の各点へ電荷を割り振ることによって求めることになります。このような方法をPIC(particle in cell)法と呼びます。解くべき方程式は、電子・イオンの運動方程式とMaxwell方程式だけです。
(Maxwell方程式の内、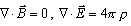 の2式は初期値として与えれば時間発展中も保存されます。(正確には特に
の2式は初期値として与えれば時間発展中も保存されます。(正確には特に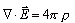 は数値誤差が無視できなくなるので補正が必要となります。))
は数値誤差が無視できなくなるので補正が必要となります。))
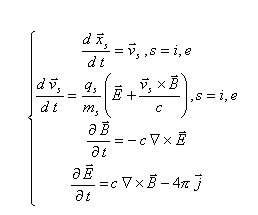
これらの手順をまとめると次のようになります。(1)運動方程式を用いて粒子位置を進める。(2)新しい粒子位置に基づいて電荷密度・電流を空間の各格子点に振り分ける。(3)Maxwell方程式によって、電場・磁場を時間発展させる。(4)計算された電磁場から粒子に働く力を求める。(5)運動方程式から粒子の速度を更新する。(6)更新された速度を用いて(1)に戻る。
実際にはスキームの組み方にはいくつものバリエーションが考えられますが、基本的な考え方は同じです。実際の計算機に載せる場合、もっとも計算時間がかかるのは(2)の粒子の電荷密度・電流の計算です。いろいろな場合によって異なりますが、粒子数が増加すればするほど(2)の比重は大きくなります。今回紹介する計算の場合ではこの部分が全体の約70%の計算時間を占めます。電磁場に関する計算量は粒子の数に比べれば圧倒的に少ないのでほとんど時間を占めないことになります。ベクトル型のスーパーコンピューターで(2)の部分を計算する場合は作業配列を用いてベクトル化する方法が確立されており、逐次プロセスで走らせる分には粒子シミュレーションのチューニングは十分になされていると言えるでしょう。さて、私たちは粒子シミュレーションコードを1世代前のVPP500/7の時代から並列化することに取り組んでいます。粒子計算は1つ1つの粒子の計算自体はまったく独立なので、一見、並列計算に非常に向いているように思えます。実際、後で示すように計算に使用するPEの数と計算時間は非常によい線型性を示します。しかし、分散メモリーの計算機環境では電磁場の計算を並列化する場合には大きな問題が生じます。今、MHD的なスケールまでを取り扱った計算がしたいので電磁場の空間格子数も多くなります。このとき、電磁場の計算時間の増加も無視できなくなるので、電磁場の計算も並列化したくなるわけです。粒子の力を計算する際には、電磁場の値をすべての粒子が参照する必要がありますが、電磁場の値を各メモリーに分散させてしまうと電磁場の分割数が多くなればなるほど非常に多くのPE間通信が発生してしまい計算時間は非常に遅くなってしまいます。現在の私たちのコードではこれを回避するために、重複ローカル配列を用意して、粒子に働く力を計算する直前に各ローカル配列に分散している電磁場の値をSPREAD MOVEで重複ローカル配列に一括転送した上で粒子に働く力を計算しています。実は、この方法でもSPREAD MOVEによるデータの転送時間によって電磁場を並列化して得られた高速化の効果がほとんど相殺されて、計算時間という点ではメリットの無い結果となってしまいました。(電磁場に関する変数のほとんどをローカル配列に分割することによって、メモリーを節約できるメリットだけは残りますが…)したがって、この問題は特に1PE当たりのメモリーが少ない計算機環境では非常に苦しい足枷となってしまいます。この点では分散メモリーよりも共有メモリーの方が向いているといえます。