VPP800のPEのベクトル性能の評価を目的に、幾つかの基本ベクトルループでのCPU時間を計測し、これまでのスパコンVPP500との比較をおこなったので、これについて報告する。
なお、プログラムはFortranで記述し、CPU時間の計測にはサービスサブルーチンCLOCKVを用い、図の縦軸は消費したCPU時間を表し、横軸のNはベクトル長を示している。
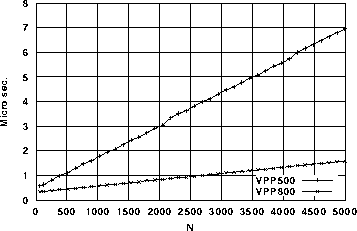
メモリアクセス性能を評価するために、x(i)=0.0およびx1(i)=x2(i)のループの計測をした。結果を図3と図4に示す。図3では、ベクトルストアではVPP500と比べるとN=500で約2倍、N=2048で約4倍の性能向上が見られる。また、図4も最大ベクトル長の2048単位で、若干の性能の劣化が見られるが、VPP500との性能差はベクトルストアーと同じような傾向であった。
図3. x(i) = 0.0
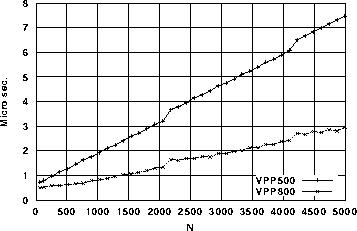
図4. x1(i) = x2(i)
次に、ベクトル演算の基本性能に関する計測を行った。乗算と除算について計測した結果を図5と図6に示す。乗算はN=2048においてVPP500と比べて約3.2倍、除算で約7.5倍の性能差が見られる。
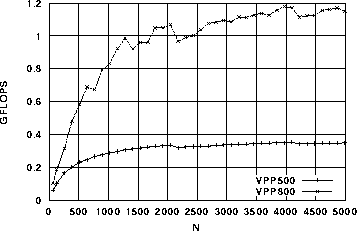
図5. x1(i) = x2(i) × x3(i)
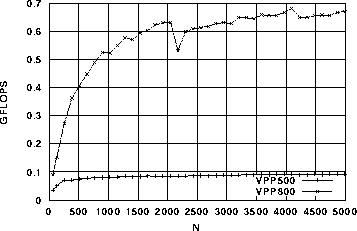
図6. x1(i) = x2(i) / x3(i)
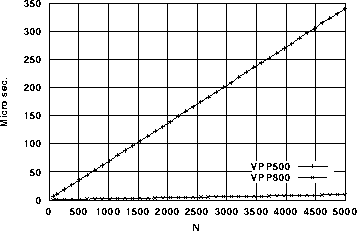
図7. x1(i) = sqrt(x2(i))
マクロ演算の性能比較のために、最大値検索、総和演算、内積の3つについて、計測した。結果を図8、図9、図10にぞれぞれ示す。VPP500との性能差は、N=2048において最大値検索で約3.2倍、総和計算で約2.7倍、内積で3.6倍であった。
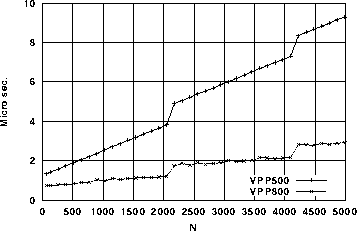
図8. xmax = max(xmax,x(i))
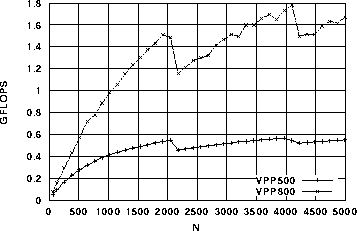
図9. s = s + x(i)
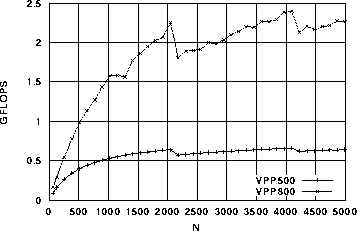
図10. s = s + x1(i) × x2(i)
本来、並列処理についても基本性能を評価すべきであるが、データがそろっていないので、本センターのVPP800で行った連立一次方程式の並列版のベンチマーク結果を表8に示す。
表8.並列版連立一次方程式のベンチマーク
| ベンチマーク名 | PE数 | 問題サイズ | 実測値(GFlops) | 実効性能比(%) |
|---|---|---|---|---|
| LINPACK Parallel | 63 | 234,360×234,360 | 482.5 | 95.7 |
| VPP-ScaLAPACK (1) | 40 | 180,000×180,000 | 286.4 | 89.5 |
| MPI-ScaLAPACK (1) | 40(1×40) | 180,000×180,000 | 271.4 | 84.8 |
| SSLII/VPP | 40 | 130,000×130,000 | 253.9 | 79.3 |
| VPP-ScaLAPACK (2) | 40 | 130,000×130,000 | 271.0 | 84.6 |
| MPI-ScaLAPACK (2) | 40(1×40) | 130,000×130,000 | 268.3 | 83.3 |
LINPACK Parallelとは、VPP800/63の全てのPEを使ったLINPACKの結果である。実効性能比95.7%は、非常にすばらしい値である。
残りベンチマークは、センターサービスで一般的に使える最大PE数40での実測結果である。
各ベンチマークの名称は、次のようになっている。
1) VPP-ScaLAPCK
現在、センター行っているScaLAPACKのVPP Fortranへの移植バージョンである。
2) MPI-ScaLAPCK
これは、VPP800で導入した製品版のMPIベースのScaLAPACKである。
3) SSLII/VPP
これは、VPP Fortran用のSSLII/VPPの連立一次方程式ルーチンdp_vlaxを指す。
これらのベンチマークは、VPP-ScaLAPCKで解ける問題サイズ18万元で他のルーチンとの性能比較のための実測したものである。また、ルーチンの構造からSSLII/VPPのdp_vlaxでは問題サイズが13万元し指定できなかった。したがって、この問題サイズ13万元についてVPP-ScaLAPACK、MPI-ScaLAPACKも計測し直したので、この値も表に載せてある。
なお、MPI-ScaLAPACKでは、プロセッサを2次元に割付けるが、今回のベンチマークでは、VPP-ScaLAPCKに合わせ1×40として実測した値であり、他の形状でプロセッサを割付ければ、より良い性能が得られるかもしれないが、今回、これを検証していない。