(4/8)
2-2.立体構造予測の10年史2-2-1.3D-1D(スレディング法)
画面16
次に、構造予測の歴史について簡単にお話しします。
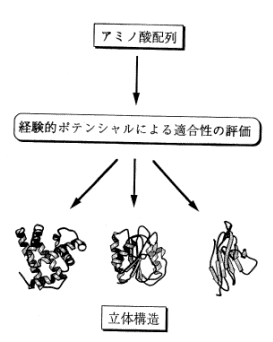
先ほどは、この研究は30年以上前から始まったと申しましたが、簡単にいうと、その間は失敗の連続でした。大勢の人がチャレンジしては、やっぱりだめだという繰り返しでした。その原因のひとつには、明らかにコンピュータパワーの不足があげられますが、それだけではありません。状況が変わったのは10年前の1990年に「3D-1D法」が考案されてからで、これを機にやっと一応まがりなりにもアミノ酸の配列から構造を予測できる確率が高くなりました。ですから、立体構造予測の歴史を実際に語るとなると、この1990年からの10年間に限られてきます。
3D-1D法とは、当時はたいへん画期的な概念でした。普通は、与えられたアミノ酸配列から立体構造をまともに考えてしまいがちですが、この3D-1D法は逆に考えます。つまり、まず答えである、あらゆる既知の立体構造(現在PDB(Protein Data Bank)では何千種類もの構造があげられます)を全て並べておき、調べたいアミノ酸配列をそのそれぞれに当てはめ、どの構造と適合しているか、計算結果のスコアを用いて数量的に評価するという方法です。最もスコアのよいものが一番適合しているだろうと予測するわけです。勿論、スコアにはある一定の基準を設けており、その基準に達していなければ解がない場合もあるので、この方法にはもともとそのような限界性もあるわけですが、アミノ酸の配列レベルでは全く違っていても、構造は似ているというケースが非常にたくさんあるので、当時、この方法は実用的に大変意味のあるものでした。
画面17
スコアで評価する方法について、実際の具体例をすこしご説明したいと思います。画面18をご覧下さい。
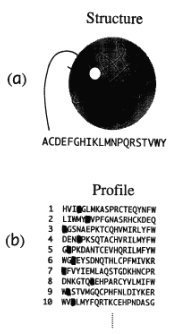
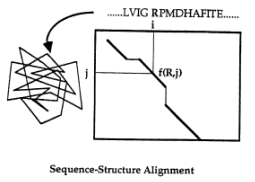
(a)はタンパクの構造で、アミノ酸の部位を描いたものです。その中のひとつの部位に注目し、アミノ酸20種類(A:アラニン、C:システィン、D、E・・・)を順番に当てはめ、ある計量的な一種のポテンシャルファンクションを勘定して、まわりとの適合性を計算し、その結果を(b)のようにテーブルにまとめていきます。このテーブルは、縦が残基番号、横が20種類のアミノ酸で、一番適合(フィット)している順にアミノ酸を並べていきます。ここで黒く印をつけているのは、天然のアミノ酸の種類です。天然のものが必ずしもトップにくるわけではありませんが、高い確率でトップに近いポジションにくることが分かります。そして、(b)のテーブルを、画面19にある立体構造のイメージ(左側)の位置に並べると、入力配列と任意の配列とのいわゆるDP (Dynamic Programming)で最適の対応関係(アライメント)が計算でき、それにより、構造と配列の最適なアラインメントが得られます。
このように、プロファイル (profile) というテーブル構造があれば、スコアをすぐに勘定することができ、それによって一応解けます。これを "3Dプロファイル型" と呼び、いわば、3D-1D法のカナメとなる考え方です。
画面18
画面19