[目次]
[発表資料]
[OHP]
質疑応答「VPP5000による乱流の直接シミュレーション」
−司会− 宇宙科学研究所 藤井孝藏
- 【司会】
- ご質疑、ご討論をお願いいたします。
- 【長屋】(富士通(株)ソフトウェア事業本部第二ソフトウェア事業部第五開発部)
- 先程、名古屋大学さんのマシンで時間がCPU時間に比してELAPS時間がかなり長くなるというご指摘をいただきましたので、回答したいと思います。現在名古屋大学さんは並列ジョブを2多重で運用していると思います。そういう意味で、課金といいますかユーザ時間を一定にするために、一旦CPUを切り離した形で運用されています。バリアなどがある程度多発するジョブについはシステムコ−ルのオーバーヘッドがきいてくると思います。一旦CPUを切り離しますので別なジョブがあればそちらに移る形になります。バリアが取れたらまた戻ってくることになり、システムのオーバーヘッドが多少増える状況になります。どのようなジョブがどれだけ増えるかは一概には言えないと思うのですが、私たちの試したジョブでは、バリアを多発するようなジョブについては3〜4倍伸びるという結果も出ています。ELAPSを短くするためには、外からsimplexやSYSPOLLなどの指定もできますので、そのあたりは名古屋大学さんとご相談して実行させていただくことをお願いしたいと思います。
- 【河村】(発表者:東京理科大学)
- 3〜4倍伸びるという結果も出ている、というのではなく、我々の場合、必ず3〜5倍になるという状態です。
- 【長屋】
- 私たちの持っている情報ですと3〜4倍伸びるケースがあります。
- 【河村】
- それは何並列くらいですか。
- 【長屋】
- 並列度といいますか、一定時間当たりのバリア(同期)をどれだけ取るかによります。すなわち、システムコールがどれだけ出るかということに依存します。
- 【河村】
- システムコールが出る度に、例えば2並列なら少し待てばできると思いますが、16、32並列になると全部揃うまで待たなければならない訳で、当然長くなると思うのですが。
- 【長屋】
- 当然2多重になった時に、並列度が増せばバラツキが出やすくなり、同期ずれの発生等が出てきます。
- 【河村】
- このプログラムの場合、ロードバランスは充分に良いので、そのようなことはほとんどない訳ですが。
- 【長屋】
- 他のジョブによって邪魔されるということです。
- 【司会】
- 名古屋大学さんのマシンは、simplexの指定はできないということですか。
- 【永井】(名古屋大学大型計算機センター)
- simplexのような形でジョブを流すことが出来ます。自分で7.5ギガバイト取るようなジョブにすればよい訳です。そして、自分でFLIB_SYSPOLLをゼロに書き換えてしまえばsimplexとほぼ同じことができるわけですが、センターとしてはあまりやって欲しくないので、もう少しプログラムを見せていただいてご相談しながらと思います。
それから先程4〜5倍という話が出ましたが、それはいつ頃のことですか。
- 【河村】
- 現在実行中のジョブです。例えば1時間CPUの時に、4〜5時間のELAPSがかかっております。
- 【永井】
- それ以前はどうだったのですか。
- 【河村】
- まだ始めて一ヶ月くらいですが、最初からずっとこのような状態です。
- 【永井】
- では、5〜6倍というのは、まだましな方かもしれないですね。(笑)
実は5倍どころではなく、1000倍くらい遅くなる可能性もあるのです。
- 【河村】
- 貴センターの相談員の方からも声を掛けていただきプログラムを見ていただきまして、改善する方向で今後もやっていこうと思います。(分科会当日以降の検討で、ELAPSとCPU時間の差は、主としてデータ通信に要する時間の可能性が高いことが判明した。)
- 【司会】
- 運用で解決できる部分のほかに、並列プロセッサを使って走る幾つものジョブとそれ以外のジョブが混在して起こる問題があるわけですね。おそらく午後の発表の中で、そのような事例のお話も出てくるかと思いますが、大事な問題提起だと思います。ですから、システム側でできることは、是非努力していただくことをお願いしたいと思います。
私から質問なのですが、並列性はリニアではなくかなり悪いのですか。
- 【河村】
- 完全にリニアではありませんが、あれくらいあれば、私どもは良いと思います。我々は、並列度をあげるほど速くなれば、並列をやっている価値があると思っています。
- 【司会】
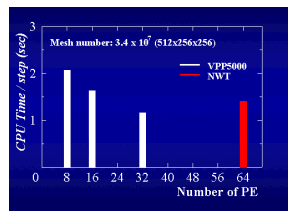
- 計算時間がNWTの8プロセッサーで0.21なのに対して、VPP5000で3.0ということは、15倍出ているわけですね。
- 【河村】
- まず、これはNWTだけの場合で、スピードアップについては、そこそこ良いと思います。それに対してこの結果(VPP)は、私は残念ながら少し足りないと思います。原因がどこにあるかは判りませんが、本来、10倍くらいは出てくれるはずなのです。というのは、少なくともスペック上で5倍、さらに並列度が下がる分がプラスされて出てくれて良いと思いますが、出ていません。この倍は速くなっても良いのかなと思います。
- 【司会】
- 確かに、仮にネットワークの負荷がないとするならば、CPUの性能ですから5倍弱出るのが自然ですね。これに対して、富士通からコメントはありますか。
- 【青木】(富士通(株)ソフトウェア事業本部ミドルウェア事業部コンパイラ技術部)
- 一度プログラムを見せて下さい。調べて見ます。
- 【司会】
- もうひとつだけ質問したいのですが、地上で起こりうるレイノルズ数でいうと、おそらく10の9乗程度まで計算できれば良いと思いますが、仮に10の9乗くらいまで直接計算できるレベルの格子点数が取れる計算機ができたとしたら、それ以上メモリは要りませんか。つまり、乱流計算に十分なメモリの上限というのはありますか。
- 【河村】
- 9乗ということにリミットしてしまえば、そういうことが言えます。宇宙の現象等では更にたくさん必要になると思いますが。(笑)
- 【司会】
- つまり、ここまでやったら充分だといえる乱流についての計算機の性能とメモリの上限が存在するのか、もしくは、ここまでやればこれが判るという、1つの階段状のところがどこかに存在するのかをお聞きしたいのですが。
- 【河村】
- 9乗でリミットしたり、また、形も決めてしまえば上限は決まります。形も複雑で、今の計算が実用と違う他の点は、今のは十分発達した流れを計算しているのに対し、現実ではデベロッピング・フローということになると思いますが、これについても入口条件が規定できれば計算できる筈ですから、そのような条件を課していけば、上限は想定できると思います。
- 【司会】
- いつになるか判りませんが。(笑)どうもありがとうございました。(拍手)
[目次]
[発表資料]
[OHP]