平成10年に機種更新で導入された現行のシステムは、データサーバー(ディスクやMTLライブラリ)とCPUサーバー間でのできるだけ速いI/Oを主眼としてデザインされた。リプロセスに対する要求は、データがかなり蓄積されていたので、すでにかなり厳しいものとなっており、データサーバーとCPUサーバー間の必要I/O性能は平均40MB/secにもなる。このような高スループットを安定的に供給できるネットワークは考えられず、データサーバーとCPUサーバーの大部分を同一のマシンで構成することが不可欠と考えられた。おりしも最大64CPUを搭載できる巨大なSMPサーバー、S-7/7000Umodel1000が発表され、データサーバーとCPUサーバーの融合が可能となったので、これを中心にシステムの構築を行った。現行システムの構成概略図を図3に示す。
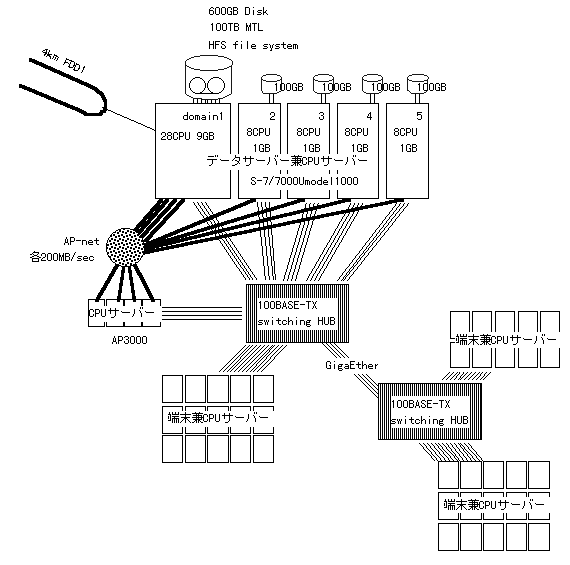
図3 SMPサーバを使った現在の構成
3.1 大容量テープライブラリ
毎年10TBものデータが蓄積されていくことから、当面100TB程度の容量として、将来的に容易に拡張することが可能なテープライブラリが検討された。また、ユーザーがテープドライブを意識した従来のシステムでは、ファイルの管理や混雑時のドライブの調停が困難となるため、階層型ファイル構造(HFS)を持ったシステムを選択した。これによって、ユーザーのアクセスは、すべて通常のディスクへのアクセスとなり、必要なファイル、利用されていないファイルは、それぞれ自動的にテープからロードあるいはテープへ保存される。また、テープドライブとのバンド幅を上げるため、12台のドライブはそれぞれ独立のFastWideSCSIでホストマシンに接続され、さらに、ディスクへの書き戻しによるオーバーヘッドを無くすためテープ内のファイルへ直接のリードファイルアクセスもサポートするシステムとした。実際導入されたシステムは容量100TBのソニー製PetaSiteとHFSソフトウェアのPetaServeである。
本システムは、ディスク上のファイルにアクセスするだけで、自動的にテープ内のデータにアクセスしたことになるので、操作性は飛躍的に向上した。しかしながら、実際に使ってみたところかなりの問題点が露呈した。
| a. |
データベースやログファイルの出力が大量のディスクスペースを必要とし、 ディスク容量のこまめな管理が必要となった。 |
| b. | ホットスワップに対応しておらず、サーバーの耐障害性が著しく低下した。 |
| c. |
制御が並列に行われないため、利用者が増えてくると、1つのドライブの巻 き戻しイジェクトの際に他のドライブが使えないなどの理由から、ドライブ の利用効率が極端に低下した。 |
| d. |
読み込み書き出しの優先度の設定が難しく、混雑時は読み込みばかりが優先 されディスクフルとなり処理が続けられなくなった。 |
| e. |
データベースやログファイルは自動的にテープにバックアップされるが、そ のサイズは予測できず、ユーザーの書き込みや変更が多いと、テープに入り きらず異常終了してしまうことがある。されに気づかなかったため、ディス ク障害時にデータの消滅が起こったことがある。 |
| f. |
ファイルの数が増えてくると、テープへ書き出す必要があるファイルを見つ けるための検索に時間がかかるようになり、高速の書き込みを続けるとディ スクフルとなってしまうことがたびたびある。 |
| g. |
通常のファイルシステムとして使え、NFS経由でのアクセスが行えるという便 利な反面、ユーザーの利用状況が把握できなかったり、混雑時には、テープ からの読み込みが遅くなり、簡単にNFSタイムアウトが起きてしまう。そのた め、ユーザープログラムでのエラーに対する特別の処置が必要となった。 |
| h. |
ファイルのテープ中への退避はオーナーしかできず、複数の人間が共同で作業 するときの障害となる。 |
など、軽微なソフト的な問題もあるが、致命的な障害となることもある。HFSシステムは便利ではあるが、使用状況に合わせて注意深くデザインしないと問題の多いシステムとなってしまう。
3.2 データサーバー兼CPUサーバー
現行システムの中心となるS-7/7000Umodel1000には、60CPU, 13GB メモリ, 1TBのRAID-5 ディスクが搭載されている。これを5つのドメインに分け、そのうちの1つをMTLに接続したデータサーバーとし、残りの4つを4つの解析グループが独自に運用できるように分配した。データサーバードメインには、28CPU, 9GBメモリ, 600GBディスクが接続されており、データ保存、リアルタイム処理、リプロセスの大部分が主としてここで実行される。残りのドメインは8CPU, 1GBメモリ, 100GBディスクを備え、各解析グループのデータ兼CPUサーバーとして働く。これらのドメインではWSと同一のプログラムが実行できるので、ホームディレクトリが共有できるなどの利便性が飛躍的に向上した。CPUサーバーとしては、単純計算で60CPUで30GFLOPSとなる。
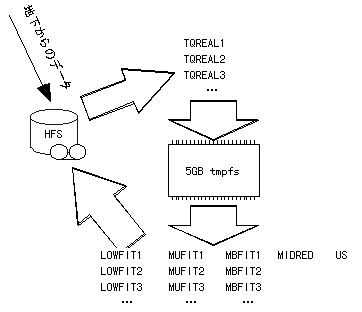
図4 現行SMP型システムでの並列処理の様子
データサーバードメイン上で実行されるリアルタイム処理やリプロセス用のプログラムは図4のようなデータの流れになっている。もっともI/O負荷のかかるバッファに使われるファイルシステムはメモリー上にtmpfsとして作られ、並列度を上げた処理が必要なときには、5GB程度をtmpfsに割り振る。このように大量なメモリを使用できるのも大規模SMPサーバーならではである。また、負荷分散はSolarisが自動的に行うので、効率よくCPUを利用するのにユーザ側での特別の並列化プログラミングは必要なく、単純に多くのプロセスを実行すればいい。また、プロセス間でのデータの分配は、ファイルのロック機構だけで容易に実現でき、プロセス間通信を使う必要はない。そのため各プロセスの独立性は高く、簡潔なプログラムで容易に並列処理が実現できる。そのためソフトウェアの信頼性やCPUの利用効率が飛躍的に向上した。これらは、共有メモリ型でこのような大規模のシステムが利用できるようになったことによる恩恵である。
導入後気づいた問題点には以下のようなものがある。
| a. |
OSの最新版のリリースが遅く、また、PetaServe等の基幹ソフトウェアで、最 新版への対応が遅いため周辺のWSとOSのヴァージョンを揃えにくい。 |
| b. |
ドメイン間でCPU資源をフレキシブルにやり取りしようとしても、S-Busボード が入っているCPUボードはその使用をやめない限り移動できない。 |
| c. |
多くのソフトウェアがホットスワップに対応していないため、故障時に無停止 での交換修理ができないことが多い。 |
| d. |
一つの計算機が巨大なため、誤操作をしたときに被る被害は甚大なものとなっ てしまうことがある。600GBのディスクが全部アクセス不能となり復旧に長期 間要しただけでなく、データの消失も起きたことがある。 |
| e. |
販売台数が少ないためか、パッチの公開が遅く、ディスクへのアクセス不能 になるような重大なトラブルが数ヶ月の間頻発するような事態に陥ったことが ある。 |
| f. |
RSM2000でデータディスクを構成しているが、2台同時にディスクが故障と判 断されるバグのためRAID-5の恩恵を受けることなくデータ消失を起こしたこと がある。 |
3.3 ネットワーク接続
本システムのネットワークは、スイッチによる100BASE-TX接続を中心として、AP-net, FDDI等による接続が行われている(図3参照)。
計算機システムが2つの棟にまたがっているため、棟間は2台の100BASE-TXスイッチングハブを4本のGigabitEthernetで接続し、各WSはこのスイッチングハブに接続する。S-7/7000Umodel1000の各ドメインは、4本の100BASE-TXでスイッチングハブに接続されバンド幅の向上が図られている。
AP-netによる接続は、4台のWSを内蔵するAP3000と5つのドメイン間で行われている。AP-netは1接続で理論値200MB/secをだせる超高速ネットワークであり、各ドメイン間の大量のデータ転送のために用いられる。また、アクセスが集中すると考えられるデータサーバードメインには4本のインターフェースを使いそれを束ねることで、1つのIPアドレスで、理論値800MB/secを出せる接続となっている。また、各ドメイン間の接続は、現在は外部ネットワーク経由での接続であるが、将来的にはGigaplaneXBによるシステムバスでの通信が可能となり、I/O性能はさらに向上する予定である。
問題点としては以下のようなものがある。
| a. |
1つのマシンに複数のネットワークインターフェースが接続されており、NIS+ によるホスト名の管理では、それぞれが異なる名前となってしまうため、ユー ザーが混乱し、効率のよいトラフィックの分散ができていない。 |
| b. |
AP-netは、理論性能は高いのであるが、チューニングをしていない通常のプロ グラムは、システムが用意しているftp, rcp, nfs等を含め、100BASE-TXと変 わらないスピードしかでない。そのため、多くのユーザーはその恩恵を得られ ていない。 |
| c. |
大型のスイッチングハブを導入することによって、どの計算機間でも十分な速 度が得られたが、ハブのファームのバグによっておきた障害は、システム全体 にわたってしまい、大きな混乱を招くことになった。 |
3.4 分散型CPUサーバー
SMP型の計算機は使いやすい反面その拡張性や、コスト面には限界がある。そのため、MCのような比較的分割しやすく、お互いの関係が薄いプロセスでは、大量の安価なWS上で実行するほうがコスト的に効率がよいことがある。本システムでは、レンタル品、購入品をあわせて約40台のWSが端末をかねて設置されており、総処理能力は理論上約40GFLOPSとなる。MCのなかには、物理の研究対象によって、CPU能力よりもI/O能力を重視するようなものもあり、そのようなものには高速のAP-netで接続されたAP3000あるいはSMPサーバーが使われる。
問題点は以下のようなものがある。
| a. | 多数のWSへジョブを投入する際には、PVMによる投入や、手作業での投入がなされているが、端末としての利用やプログラム中でのI/O待ちなどを考えた場合、CPUロードを効率よく100%、まで使うのが難しい。 |
| b. | データの出力先となるリモートのホスト名が、ジョブを投入されるWSによって異なることがあるため、スクリプトの準備が煩わしい。 |
| c. | ジョブを分割した場合、乱数系列の整合性が難しく、ある時点から同じ乱数でシミュレーションを始めてしまう危険性がある。 |
| d. | データサーバーの独立性を高めるため、また負荷分散や保守性を考えて、ホームディスクや /usr/local/bin、/var/mail の他、いくつかのライブラリが複数のWSに分かれて配置されている。そのため、クロスマウントがさけられず、一台のシステム停止が、システム全体に影響を及ぼすことがある。 |