科学技術計算分科会2014年度会合 分科会レポート
次世代HPCを支える技術
2014年10月24日に科学技術計算分科会の秋イベントが神戸のホテルオークラにて開催された。今回のテーマは“次世代HPCを支える技術”である。HPCアプリケーションやアーキテクチャ、次世代機の性能紹介、パネルディスカッションと興味深い講演で構成されており、約90名の参加者が活発な議論を繰り広げた。
スーパーコンピュータを用いた大規模グラフ解析とGraph500ベンチマーク
最初の発表は「スーパーコンピュータを用いた大規模グラフ解析とGraph500ベンチマーク」と題する九州大学の藤澤克樹氏の講演である。

グラフとは点と枝を組み合わせた構造のことで、ソーシャルネットワークや交通ネットワーク、ニューラルネットワーク、ロジスティックネットワークなどを表現できる。例えば、交通ネットワークの場合は交差点を"点"として、交差点に接する道路を"枝"として表現する。全米の交通網は約2,400万点、5,800万枝で表現でき、最新のグラフ解析アルゴリズムでは全米を横断するような最短経路を約2秒で探索するという(Intel Xeon 5670 2.93GHz)。近年では、数億〜数兆点からなる超大規模グラフをスーパーコンピュータで解析するアルゴリズムについての研究を行っているとのことだ。グラフ解析ではある点を決めてその点から幅優先探索(BFS)を行う場合に、Top-down BFS(対象の点から出ていく枝をたどる)とBottom-down BFS(未探索の点に入ってくる枝をたどる)アルゴリズムを組み合わせたHybrid BFS手法を用いることで、探索する枝の数を大幅に減らすことができ大幅な高速化が果たせたという。また最近ではグラフの特徴を示す指標として点の中心性指標が研究されている。中心性指標の一例として、各点が最短路に含まれる回数(Betweenness Centrality)を計算すると、グラフ中の重要な点が浮かび上がるという。このような点は、交通ネットワークであれば橋であり、ソーシャルネットワークであれば影響度の高い人物となる。
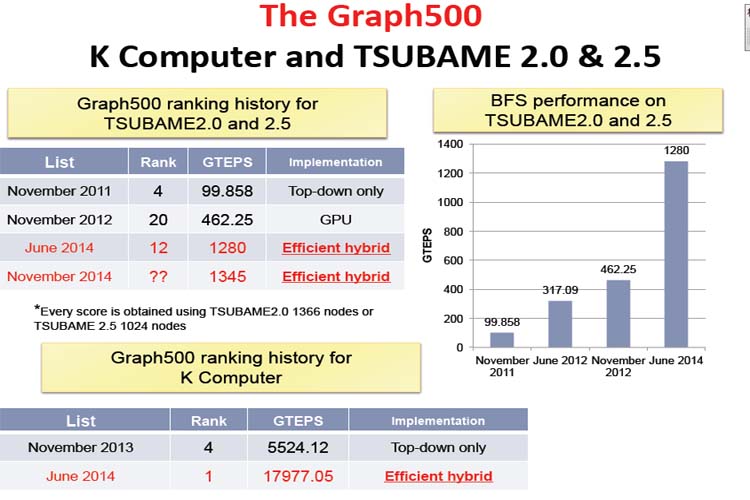
Graph500は2010年から始まったグラフの探索速度を競うランキングで幅優先探索での一秒当たりの探索枝数TEPS(# of Traversed edges per second)という指標で評価される。2014年6月のランキングでは「京」コンピュータの65,536ノードを使って約18,000 GTEPSで1位の結果であったという。また、Green Graph500という消費電力あたりのTEPS(TEPS/W)で評価されるランキングがあり、小さなデータサイズであればスマートフォンが高い性能を示すという。
分子動力学計算専用計算機MDGRAPE-4の開発
次の講演は理化学研究所の泰地真弘人氏による「分子動力学計算専用計算機MDGRAPE-4の開発」である。

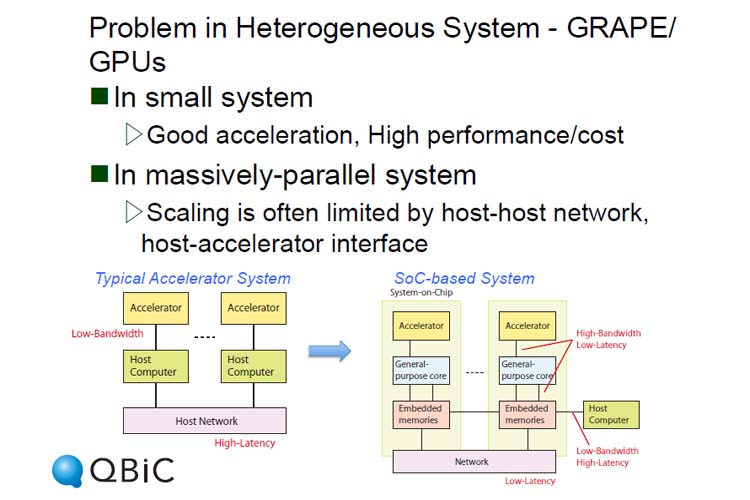
GRAPEは1989年から開発が始まった重力多体問題を解くための専用計算機である。原子を星と思えば、分子にも応用できるということで開発されたのが分子量力学計算の専用計算機であるMDGRAPEシリーズだ。現在、MDGRAPH-4はハードウェアがほぼ完成し、分子動力学シミュレーションソフトウェアであるGROMACS 5を移植中とのことだ。MDGRAPE-4の特徴はアクセラレータと汎用コアおよびネットワークをSoC(System-on-Chip)に集積したことだ。1ノードに8つのSoCを搭載し、ノード間のネットワークには光を使い、3次元トーラスネットワークで構成される。ネットワークが低レイテンシ・高バンド幅となったことで先代のMDGRAPE-3より並列性能が向上した。MDGRAPE-3はホストコンピュータ上にアクセラレータを搭載するアーキテクチャであり、アクセラレータ間の通信はホストを経由するためレイテンシが高く並列性能に限界があったという。また、TOP500リストに載るコンピュータの平均CPU周波数は2006年以降では2.5GHz程度と停滞していることを示し、ますます性能向上が困難になっており、今後の高性能計算のためにはさらなる並列化が必要だという。エクサに向けては、生命科学計算は「京」クラスの計算をより高い実効性能で多量に実行する「京」コンピューティングの実現が重要であるとのことだ。
京コンピュータを使った地盤震動シミュレーションの現状 [本人確認済]
次の講演は理化学研究所の藤田航平氏による「京コンピュータを使った地盤震動シミュレーションの現状」であった。

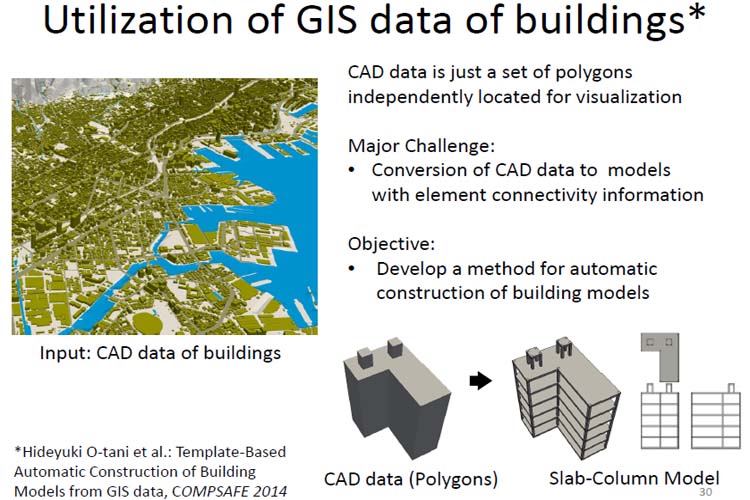
地震のシミュレーションでは、地盤の動きだけでなくその上の建築構造物も含めてシミュレーションを行うという。都市地震シミュレーションの例として地盤のモデル化、建築構造物のモデル化についての研究が紹介された。「地殻中の波動伝搬」と「構造物解析」は独立して従来から盛んに研究されていたが、現在は都市スケールの地盤振動問題が重要であるという。都市の地表から100m程度の地盤は堆積や浸食などで複雑な物性分布となっており、特定の周波数成分によっては10倍程度の増幅がかかることもあるという。これは構造物の地震被害に大きく影響する。地盤の上の構造物として一般的なのはコンクリートであるが、コンクリートといってもその物性は同じ設計でも実際の性能にはばらつきがある。このような不確実性も被害想定に含めることが望ましく、入力分布に対する結果の分布のように統計的にシミュレーションを行うという。また、地盤のどの部分にどのような建物(木造・コンクリート等)が存在するかということは、地図情報や固定資産税の情報(鉄筋コンクリート造/木造)から推定するという。構造物解析には柱の位置が重要であるが、これらも建物と柱の位置のモデルをテンプレート化し、それらを地図情報(建物の形)から当てはめることで推定する。様々な手法や情報を組み合わせてより現実に近い都市をコンピュータ上で再現し、その上で地震をシミュレーションすることでより現実に近い被害状況の推定が可能だという。
PRIMEHPC FX10後継機における性能と評価
最後の講演は富士通株式会社の千葉修一氏による「PRIMEHPC FX10後継機における性能と評価」であった。

発表内容は開発中のFX10後継機で計測したカーネルコードやSTREAMベンチマーク、姫野ベンチマーク結果の紹介である。後継機のCPUはSPARC64 XIfxで、32+2コア構成で2つのアシスタントコアがOSやMPIの処理を行い、計算に対するノイズの低減や通信と計算のオーバーラップを実現する。またFX10で課題であったコンパイラの最適化や命令レベルの並列性、L1キャッシュの容量について、それぞれHPC-ACE2と呼ぶ256bit wide SIMDの導入、HMC採用によるメモリスループットの向上、L1/L2キャッシュ容量の倍増、コンパイラの最適化/並列化解析能力の強化が行われているという。
性能紹介では、1コア性能/SIMD性能/スレッド並列化性能/アプリケーション性能の4つの観点から評価が行われた。1コア性能ではSIMD性能においてSIMD幅が128bitから256bitに強化されたため、FX10に比べて平均で約2.16倍の性能向上を達成したという。スレッド並列化性能ではコンパイラの解析能力を判定するベンチマークプログラムを用いてIntelコンパイラよりも高い並列化解析能力があることが示された。VPPの技術を取り入れて解析能力を強化したためで、今後「京」やFX10のコンパイラへもフィードバックするという。アプリケーション性能ではNAS Parallel benchmarkやOpenFOAMの評価が紹介され、L1キャッシュを倍増した効果や整数演算性能を向上させた効果がアプリケーションでも確認できた。ハードウェアとコンパイラの性能向上により、「京」やFX10のアプリケーションがチューニングレスにFX10後継機でさらに性能向上することが期待される。

懇談会「GPU vs MIC あなたの選択はどっち?」
発表は以上で、その後会場を移して懇談会が行われた。懇談会では「GPU vs MIC あなたの選択はどっち?」と題するパネルディスカッションが行われ、パネリストがGPU派とMIC派に分かれて、それぞれのアーキテクチャの利点と欠点について議論した。GPUは性能は高いがコーディングが難しく、高度なチューニングにはかなりの勉強が必要だという問題がある。また将来的にGPUがメインストリームにならなかった場合にそれまでの勉強時間やコード資産が無駄になるとの不安の声もあった。一方MICはコーディングは基本的に今までと同じため移植性は高く、利用者にも受け入れやすい。しかし、今のところ性能に問題があるとのことで今後に期待しているとのことだ。
以上