タンパク質立体構造の予測問題
|
 国立遺伝学研究所 西川 建 |
(1/8)
1. DDBJについて本日は、このような場で発表させていただく機会を得てたいへん光栄に思っております。
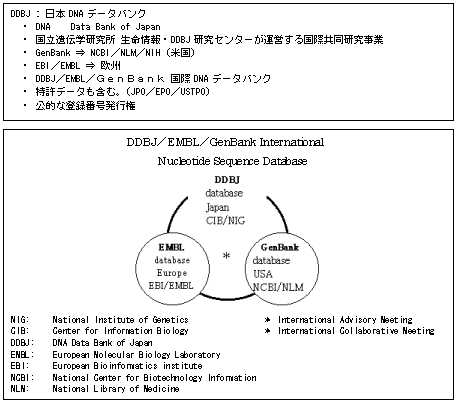
まず本題に入る前に、DDBJ (DNA Data Bank of Japan) の宣伝をさせていただきます。DDBJとは、我々が所属する国立遺伝学研究所が運営している日本DNAデータバンクで、主に日本で決められたDNA配列を受け付け登録しています。
さらに、アメリカ、ヨーロッパと協同で、国際塩基配列データベース (Nucleotide Sequence Database) を構築しており、主にDNAの塩基配列データを収集・編集し、全世界に提供しています。
画面1
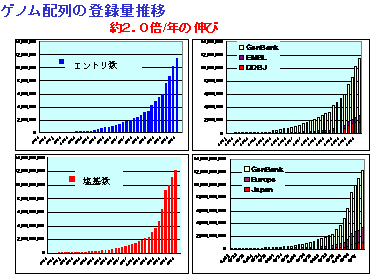
画面2は、国際塩基配列データベースに登録されたゲノム配列の登録量をグラフ化したものです。右側のグラフは、DDBJ(日本)、GenBank(アメリカ)、EMBL(ヨーロッパ)の内訳を示したものですが、GenBankの登録量が最も多く、DDBJは全体のおよそ1割に貢献していることが判ります。
画面2
画面3は、DDBJのホームページです(http://www.ddbj.nig.ac.jp/Welcome-j.html)。塩基配列の登録の仕方や、データベース検索、そして、これからお話する立体構造の予測などのサービスは全てこのホームページ上で運営しています。なお、ユーザが実際にDDBJにデータを登録される際には、ホームページ内の「sakura」というシステムをご利用いただいております。
画面3
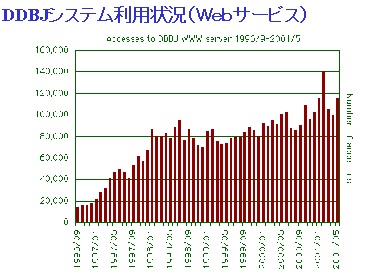
DDBJホームページの利用状況は、画面4に示す通りです。一月におよそ10万件ほどのアクセスがあることが判ります。
DDBJには、実際のデータフローに携わる者と、内容をチェックするレビューワーと呼ばれている者、ソフトウェアを開発するSE、そしてシステムの管理者など、合計で50〜60人以上がおり、ちょっとした会社並みの規模で活動をしています。ホストは、今年から富士通さんのVPP5000を導入しています。今後も多くの皆さまにDDBJをご活用いただきたく思っております。
画面4