3.1レベル1ルーチンのチューニング
図1にレベル1ルーチンDAXPYのオリジナルのベクトル化リストを示す。このリストから分かるようにループ(DO 50)に4重のアンローリングが施されている。
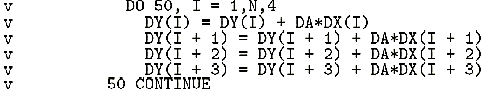 |
図1. DAXPYのオリジナルのベクトル化リスト
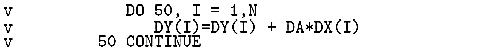 |
図2. DAXPYのアンローリングを抑止したベクトル化リスト
このチューニング方法は、スカラ演算の場合には、ループを繰り返すための演算を4分の1に減らすので有効である。しかし、ベクトル演算では、ループの繰返し回数をベクトル長として一括してベクトル処理するために、ベクトル化の対象である最内ループに対するアンローリングは、ベクトル長を短くする事になり、かえって性能劣化を招く[4]。したがって、この最内ループでのアンローリングを抑止した(図2)。
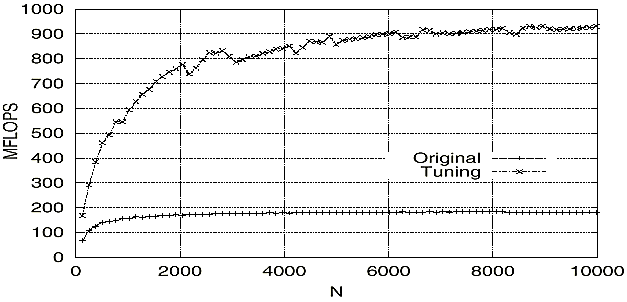
図3はDAXPYのベンチマーク結果である。横軸は扱うベクトルの大きさN、縦軸は演算量を2Nとして求めたMFLOPS値である。なお、CPU時間の測定にはサービスサブルーチンCLOCKV[5]を用いた。
図3のOriginalがアンローリングを施した場合、Tuningがアンローリングを抑止した場合の結果を示している。Originalは、Nが2000を越えると飽和してしまい200MFLOPSも出ていない。一方、Tun-ingはNが10000で900MFLOPSとなり、Originalと比べると約4.5倍の性能が得られている。
このようなコーディングはレベル1のDASUM,DCOPY,DDOT,DSCAL,DSWAPの6つのルーチンに見られ、同様にアンローリングを抑止した。
3.2行列積ルーチンでのチューニング
線形代数の計算においては、その使用頻度から行列積ルーチンの性能が重要であり、また、ベクトルチューニングの効果が大きい[2][3]。
したがって、まず、レベル3の一般行列の行列積ルーチンDGEMMに対するチューニングを検討した。なお、DGEMMが扱う式は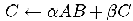 である。また、引数で、行列A; Bを転置行列として扱い計算することが指定できる。しかし、ここでは、いずれの行列も転置でない場合について議論する。
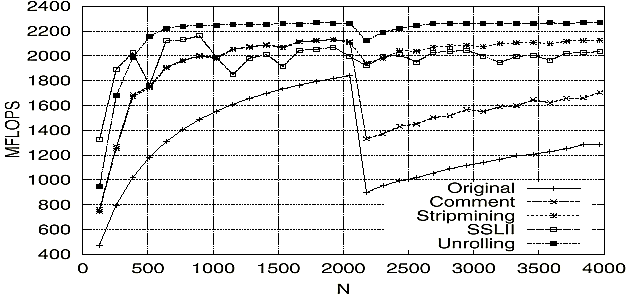
図4は、DGEMMのチューニングの評価のために行ったベンチマークの結果をまとめたものである。測定は大きさN × Nの行列を用い、横軸のNは行列の大きさ表し、縦軸は演算量を
である。また、引数で、行列A; Bを転置行列として扱い計算することが指定できる。しかし、ここでは、いずれの行列も転置でない場合について議論する。
図4は、DGEMMのチューニングの評価のために行ったベンチマークの結果をまとめたものである。測定は大きさN × Nの行列を用い、横軸のNは行列の大きさ表し、縦軸は演算量を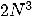 として求めたMFLOPS値を表している。
として求めたMFLOPS値を表している。
3.2.1自動ベクトルアンローリングの促進
図5に、DGEMMのオリジナルのベクトル化リストの一部を示す。本来、行列積の3重ループでは、中間ループでアンローリング(ベクトルアンローリング)がコンパイラの最適化機能によって施される。しかし、BLASのコーディングでは、中間ループ(DO 80)の配下にIF文が置かれ、最内ループ(DO 70)の実行が制御されているために自動ベクトルアンローリングの対象とならない。
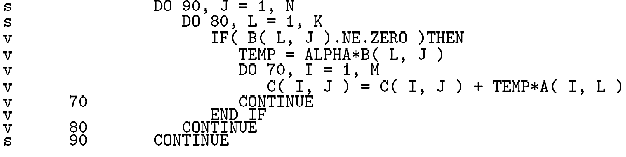 |
図5. DGEMMのオリジナルのベクトル化リスト
図6がIF文を削除した後のベクトル化リストである。先頭のv2という表示から2重のアンローリングがコンパイラにより施されたことが分かる。
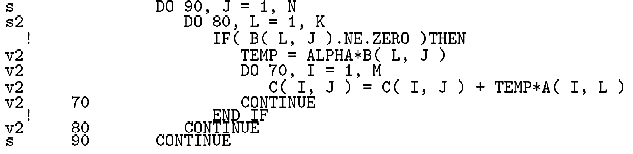 |
図6. DGEMMのIF文を削除したベクトル化リスト
3.2.2ストリップマイニングの適用
図4のOriginal,CommentからNが2048を越えると、性能が極端に落ちていることがが分かる。
このような性能劣化に対するベクトルチューニング手法としてストリップマイニングがある[1]。図7にストリップマイニングを施した後のベクトル化リストを示す。
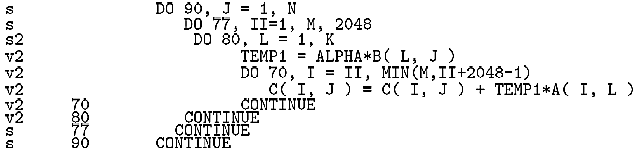 |
図7. DGEMMのストリップマイニングを施したベクトル化リスト
図4のStripminingがストリップマイニングを施した後の結果である。このチューニングで最大ベクトル長を超えたことによる性能劣化が解消できたことが分かる。
3.2.3最外ループでのアンローリング
図8は、さらに、最外ループ(DO 90)で2重のアンローリングを施した後のベクトル化リストである。
このアンローリングにより、最内ループ(DO 70)での配列Aのデータのロード回数を1/2にでき、かつ、演算密度が2倍になる。
図4のUnrollingが最外ループ(DO 90)でアンローリングを施した後の結果である。このチューニングの結果、Nが600を超えるあたりから、VX/2の最大ベクトル演算性能である2.2GFLOPSが得られている。
 |
図8.最外ループでのアンローリング施したベクトル化リスト
図4のSSLIIはDGEMMに対するチューニングを評価する目的に、メーカ開発のベクトル版SSLIIの行列積ルーチンDVMGGM(V13L10+PTF95111)を同じ条件でベンチマークした結果である。
UnrollingとSSLIIを比較すると、Nが500以下ではSSLIIに負けるが、500を超えるとSSLIIの性能を上回り、Nの最大4000では、その差は約230MFLOPS(10%増)となっている。このことからDGEMMに対するチューニングは、充分であると考える。
3.3 DGEMMでのチューニング手法の他のルーチンへの適用
DGEMMで用いたチューニング手法の効果が充分に確認できたので、ここで用いたチューニング手法を他のルーチンにも適用することを検討した。その結果、次のようなルーチンに対して有効であった。
- IF文の削除による自動ベクトルアンローリング
レベル2でDGEMV, DGER、レベル3でDSYRK,DSYR2K,DTRMM,DTRSMの6つのルーチン。 - ストリップマイニング
1.に掲げるルーチンの中でDGERを除く、他の5つのルーチン。
3.4.1三角方程式でのチューニング
図11は、レベル3ルーチンDTRSMに現れるコーディングで、行列Aが転置しない下三角行列について、AX = Bの解を求めるものである。
 |
図9. DTRSMのオリジナルのベクトル化リスト
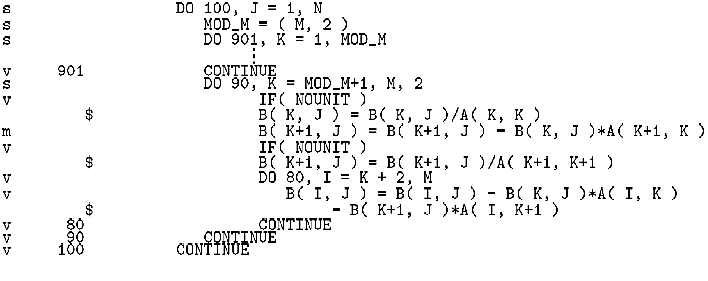 |
図10. DTRSMのアンローリングを施したベクトル化リスト
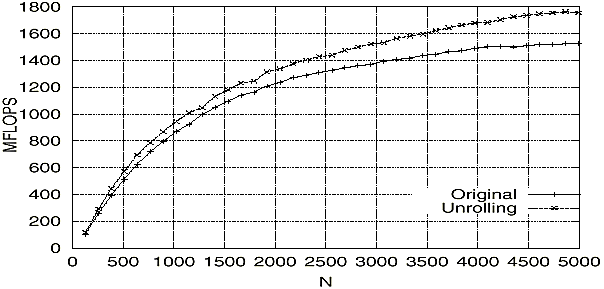
 -Nとして求めたMFLOPS値である。Originalはオリジナルの結果、Unrollingはアンローリングを施した後の結果である。Nが大きくなるにつれてアンローリングの効果が現れ、Nの最大5000で、UnrollingはOriginalに比べ、性能が約230MFLOPS(15%増)上回っている。
-Nとして求めたMFLOPS値である。Originalはオリジナルの結果、Unrollingはアンローリングを施した後の結果である。Nが大きくなるにつれてアンローリングの効果が現れ、Nの最大5000で、UnrollingはOriginalに比べ、性能が約230MFLOPS(15%増)上回っている。
同じコーディングは、レベル2でDSYR,DSYR2,DTRMV,DTRSV、レベル3でDTRMMの5つのルーチンがあり、同一のチューニングを施した。
3.4.2最適化制御行によるベクトル化の促進
コンパイラにオプション-Wv,-m3を指定すると、コンパイル時にベクトル化の詳細なメッセージを得ることができる。
一般行列とベクトルの積を計算するDGEMVをこのオプションを指定してコンパイルすると、次のようなベクトル化メッセージか出力された。
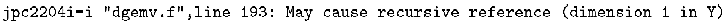
これは、配列Yで回帰参照となる可能性があるのでベクトル化できなかったことを通知している。問題になったコーディングを図12に示す。
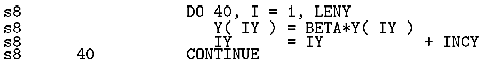 |
図12. DGEMVのオリジナルのベクトル化リスト
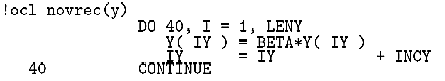 |
図13. DGEMVの最適化指示子を挿入したベクトル化リスト